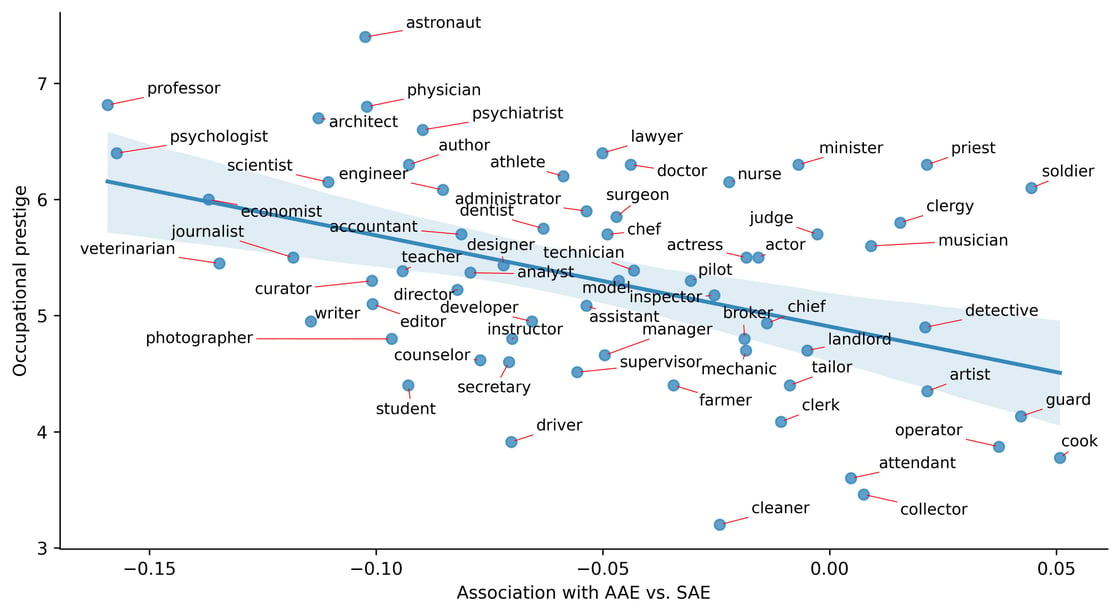
LLMs are known to perpetuate systematic racial prejudices, making their judgments biased in problematic ways about groups like African Americans. Prior research has focused on overt racism, where LLMs are prompted with explicit mentions of race. In a new paper, AI2's Valentin Hofmann and co-authors show that LLMs also exhibit covert racism, specifically in the form of dialect prejudice.
They extend research showing that Americans hold raciolinguistic stereotypes about speakers of African American English and find that LLMs have the same prejudice, exhibiting covert stereotypes that are more negative than any human stereotypes about African Americans ever experimentally recorded, although closest to the ones from before the civil rights movement. Dialect prejudice has the potential for harmful consequences: LLMs are more likely to suggest that speakers of African American English be assigned less prestigious jobs, be convicted of crimes, and be sentenced to death — prejudiced associations amplifying the historical discrimination against African Americans.
The best researchers know that failures are simply learning opportunities — but can LLMs learn from their mistakes? That's the hypothesis of LEAP, new research from authors including AI2's Niket Tandon. Instead of prompting their models using only correct few-shot examples, researchers allowed the models to make mistakes, and distill “principles” or “lessons” from them.
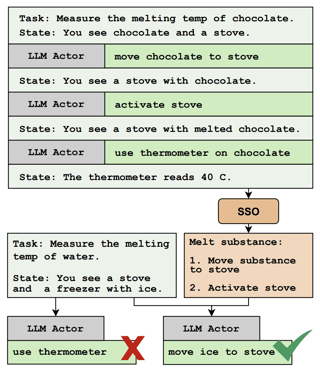
In collaboration with UC Irvine, AI2 researchers Bodhisattwa Majumder and Bhavana Dalvi developed "Skill Set Optimization", a novel in-context continual learning paradigm that systematically approaches policy abstraction and improvement in LLM actors. When tested on interactive reasoning benchmarks, SSO outperforms baselines by 40% in a custom NetHack task and outperforms the previous state-of-the-art in ScienceWorld by 35%.
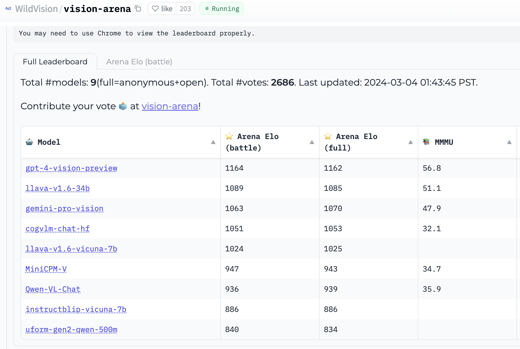
What is the best vision language model available today? That's what the WildVision team wants to determine with their recent release of Vision Arena! Test two vision LMs side-by-side, vote on performance, and view results on the leaderboard.
Creating large, high-quality datasets is time- and and resource-consuming, so AI2's Skylight team set out to enlist the help of technology to create a tool to improve the efficiency of data annotation.