Videos
See AI2's full collection of videos on our YouTube channel.Viewing 151-160 of 252 videos

Debiasing natural language evaluation with humans in the loop
March 28, 2018 | Arun ChagantyA significant challenge in developing systems for tasks such as knowledge base population, text summarization or question answering is simply evaluating their performance: existing fully-automatic evaluation techniques rely on an incomplete set of “gold” annotations that can not adequately cover the range of…
Text Representation, Retrieval, and Understanding with Knowledge Graphs
March 26, 2018 | Chenyan XiongSearch engines and other information systems have started to evolve from retrieving documents to providing more intelligent information access. However, the evolution is still in its infancy due to computers’ limited ability in representing and understanding human language. This talk will present my work…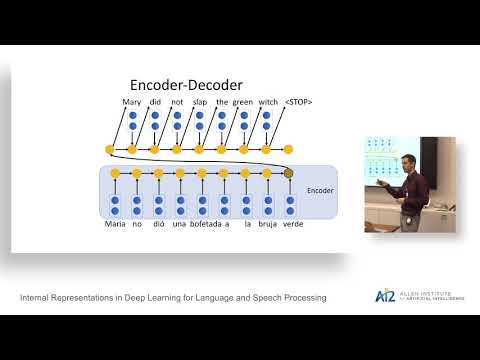
Internal Representations in Deep Learning for Language and Speech Processing
March 7, 2018 | Yonatan BelinkovLanguage technology has become pervasive in everyday life, powering applications like Apple’s Siri or Google’s Assistant. Neural networks are a key component in these systems thanks to their ability to model large amounts of data. Contrary to traditional systems, models based on deep neural networks (a.k.a. deep…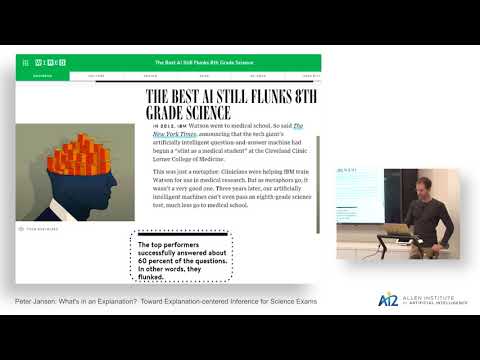
What's in an Explanation? Toward Explanation-centered Inference for Science Exams
March 2, 2018 | Peter JansenModern question answering systems are able to provide answers to a set of common natural language questions, but their ability to answer complex questions, or provide compelling explanations or justifications for why their answers are correct is still quite limited. These limitations are major barriers in high…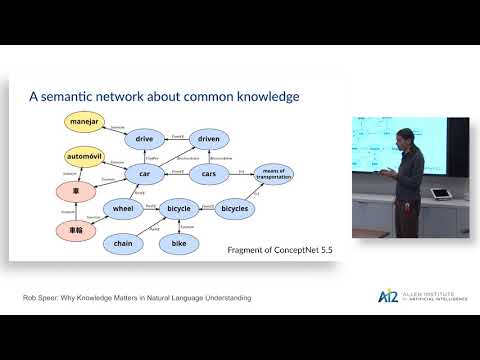
Why Knowledge Matters in Natural Language Understanding
February 27, 2018 | Rob Speer and Catherine HavasiWe are the developers of ConceptNet, a long-running knowledge representation project that originated from crowdsourcing. We demonstrate systems that we’ve made by adding the common knowledge in ConceptNet to current techniques in distributional semantics. This produces word embeddings that are state-of-the-art at…
Semantic Role Labeling with Labeled Span Graph Networks
February 26, 2018 | Luheng HeSemantic role labeling (SRL) systems aim to recover the predicate-argument structure of a sentence, to determine “who did what to whom”, “when”, and “where”. In this talk, I will describe my recent SRL work showing that relatively simple and general purpose neural architectures can lead to significant performance…Oren Etzioni on Demystifying Artificial Intelligence
February 13, 2018 | Oren EtzioniOren Etzioni, CEO of the Allen Institute for AI, gave the keynote address at the winter meeting of the Government-University-Industry Research Roundtable (GUIRR) on "Artificial Intelligence and Machine Learning to Accelerate Translational Research".
Image Synthesis for Self-Supervised Learning
February 12, 2018 | Richard ZhangWe explore the use of deep networks for image synthesis, both as a graphics goal and as an effective method for representation learning. We propose BicycleGAN, a general system for image-to-image translation problems, with the specific aim of capturing the multimodal nature of the output space. We study image…
Experiments in Inferring Latent Sentence Structure
January 17, 2018 | Alexander RushEarly successes in deep generative models of images have demonstrated the potential of using latent representations to disentangle structural elements. These techniques have, so far, been less useful for learning representations of discrete objects such as sentences. In this talk I will discuss two works on…
From Reading Comprehension to Open-Domain Question Answering
November 21, 2017 | Danqi ChenEnabling a computer to understand a document so that it can answer comprehension questions is a central, yet unsolved, goal of NLP. This task of reading comprehension (i.e., question answering over a passage of text) has received a resurgence of interest, due to the creation of large-scale datasets and well…