Videos
See AI2's full collection of videos on our YouTube channel.Viewing 21-30 of 258 videos

Studying Large Language Model Generalization with Influence Functions
October 31, 2023 | Roger GrosseAbstract: When trying to gain better visibility into a machine learning model in order to understand and mitigate the associated risks, a potentially valuable source of evidence is: which training examples most contribute to a given behavior? Influence functions aim to answer a counterfactual: how would the…
Modular Language Models
October 16, 2023 | Suchin GururanganConventional language models (LMs) are trained densely: all parameters are updated with respect to all data. We argue that dense training leads to a variety of well-documented issues with LMs, including their prohibitive training cost and unreliable downstream behavior. We then introduce a new class of LMs that…
Towards Cost-Efficient Use of Pre-trained Models
October 10, 2023 | Alan RitterAbstract: Large language models are leading to many exciting breakthroughs, but this comes at a significant cost in terms of both computational and data labeling expenses. Training state-of-the-art models requires access to high-end GPUs for pre-training and inference, in addition to labeled data for fine-tuning…
Reliability and interactive debugging for language models
October 6, 2023 | Bhargavi ParanjapeAbstract: Large language models have permeated our everyday lives and are used in critical decision making scenarios that can affect millions of people. Despite their impressive progress, model deficiencies may result in exacerbating harmful biases or lead to catastrophic failures. In this talk, I discuss several…
The University of Washington eScience Institute: a Home for Data-Intensive Discovery
September 27, 2023 | Sarah Stone, Executive Director, eScience Institute, University of WashingtonAbstract: The University of Washington eScience Institute, one of the nation's first university data science institutes, grew out of the Moore-Sloan Data Science Environment effort which was focused on identifying and tackling impediments to the broad and sustainable adoption of data-intensive discovery. With a…
Reliable Evaluation and High-Quality Data: Building Blocks for Helpful Question Answering Systems
September 26, 2023 | Ehsan KamallooAbstract: As models continue to rapidly evolve in complexity and scale, the status quo of how they are being evaluated and the quality of benchmarks has not significantly changed. This inertia leaves challenges in evaluation and data quality unaddressed, which results in the potential for erroneous conclusions…
Vision Without Labels
September 13, 2023 | Bharath Hariharan/Cornell UniversityBio: Bharath Hariharan is an assistant professor at Cornell University. He works on problems in computer vision and machine learning that defy the big data label. He did his PhD at University of California, Berkeley with Jitendra Malik. His work has been recognized with an NSF CAREER and a PAMI Young Researcher…
Skill-it! A Data-Driven Skills Framework for Understanding and Training Language Models
August 31, 2023 | Mayee Chen, PhD Student, Stanford UniversityBio: Mayee Chen is a PhD student in the Computer Science department at Stanford University advised by Professor Christopher Ré. She is interested in understanding and improving how models learn from data. Recently, she has focused on problems in data selection, data labeling, and data representations, especially…
From Compression to Convection: A Latent Variable Perspective
August 30, 2023 | Prof. Stephan Mandt/UC IrvineAbstract: Latent variable models have been an integral part of probabilistic machine learning, ranging from simple mixture models to variational autoencoders to powerful diffusion probabilistic models at the center of recent media attention. Perhaps less well-appreciated is the intimate connection between latent…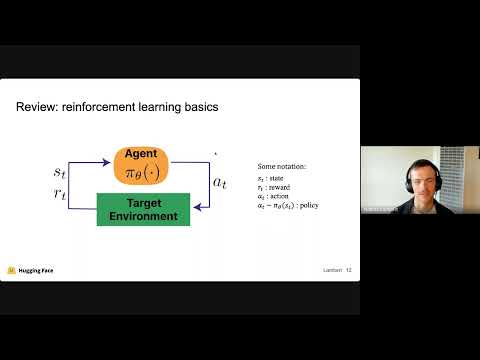
Objective Mismatch in Reinforcement Learning from Human Feedback
August 29, 2023 | Nathan LambertAbstract: Reinforcement learning from human feedback (RLHF) has been shown to be a powerful framework for data-efficient fine-tuning of large machine learning models toward human preferences. RLHF is a compelling candidate for tasks where quantifying goals in a closed form expression is challenging, allowing…