DIY Information Extraction
Data scientists have a set of tools to work with structured data in tables. But how does one extract meaning from textual data? While NLP provides some solutions, they all require expertise in either machine learning, linguistics, or both. How do we expose advanced AI and text mining capabilities to domain experts who do not know ML or CS?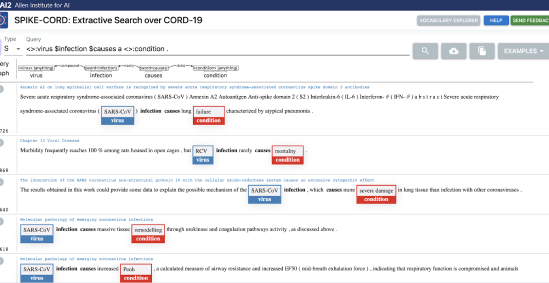
Powerful extractive search | AI2 Israel, DIY Information Extraction
SPIKE is a powerful sentence-level, context-aware, and linguistically informed extractive search system. Try SPIKE over one of our provided datasets.
Try the demo
Powerful extractive search | AI2 Israel, DIY Information Extraction
SPIKE is a powerful sentence-level, context-aware, and linguistically informed extractive search system. Try SPIKE over one of our provided datasets.
Try the demoRecent Papers
From Centralized to Ad-Hoc Knowledge Base Construction for Hypotheses Generation.
Shaked Launer-Wachs, Hillel Taub-Tabib, Jennie Tokarev Madem, Orr Bar-Natan, Yoav Goldberg, Y. ShamayJournal of Biomedical Informatics • 2023 Objective To demonstrate and develop an approach enabling individual researchers or small teams to create their own ad-hoc, lightweight knowledge bases tailored for specialized scientific interests, using text-mining over scientific literature, and…Interactive Extractive Search over Biomedical Corpora
Hillel Taub-Tabib, Micah Shlain, Shoval Sadde, Dan Lahav, Matan Eyal, Yaara Cohen, Yoav GoldbergACL • 2020 We present a system that allows life-science researchers to search a linguistically annotated corpus of scientific texts using patterns over dependency graphs, as well as using patterns over token sequences and a powerful variant of boolean keyword queries…pyBART: Evidence-based Syntactic Transformations for IE
Aryeh Tiktinsky, Yoav Goldberg, Reut TsarfatyACL • 2020 Syntactic dependencies can be predicted with high accuracy, and are useful for both machine-learned and pattern-based information extraction tasks. However, their utility can be improved. These syntactic dependencies are designed to accurately reflect…Syntactic Search by Example
Micah Shlain, Hillel Taub-Tabib, Shoval Sadde, Yoav GoldbergACL • 2020 We present a system that allows a user to search a large linguistically annotated corpus using syntactic patterns over dependency graphs. In contrast to previous attempts to this effect, we introduce a light-weight query language that does not require the…






