Videos
See AI2's full collection of videos on our YouTube channel.Viewing 1-10 of 261 videos
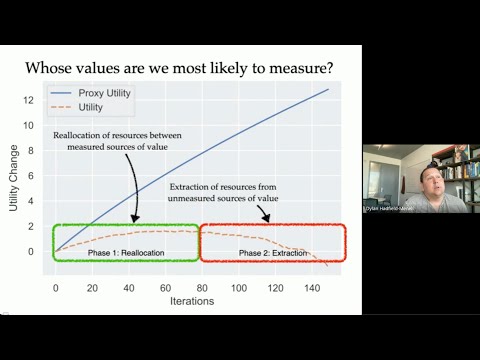
You Can't Have AI Safety Without Inclusion
July 10, 2024 | Dylan Hadfield-MenellAbstract: The challenge of specifying goals for agents has long been recognized, as Kerr's seminal 1975 paper 'On the Folly of Rewarding A while Hoping for B' highlights the unintended consequences of misaligned reward systems. This issue lies at the heart of AI alignment research, which seeks to design incentive…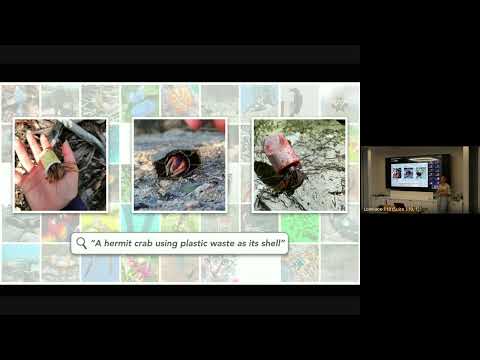
AI-enabled scientific discovery in natural world imagery
June 20, 2024 | Sara BeeryAbstract: Natural world images collected by communities of enthusiast volunteers provide a vast and largely uncurated source of data. For instance, iNaturalist has over 180 million images tagged with species labels, already contributing immensely to research such as biodiversity monitoring and having been cited…
Concept Bottleneck Models for Text Classification
June 7, 2024 | Josh Magnus LudanInterpretable-by-Design Text Understanding with Iteratively Generated Concept Bottleneck https://arxiv.org/abs/2310.19660 Josh Magnus Ludan, Qing Lyu, Yue Yang, Liam Dugan, Mark Yatskar, Chris Callison-Burch Black-box deep neural networks excel in text classification, yet their application in high-stakes domains…
The Pre-trainer's toolkit: From dataset construction to model scaling
May 6, 2024 | Samir Yitzhak GadreAbstract: Recent breakthroughs in machine learning rely heavily on pre-training techniques, harnessing larger datasets, models, and computational resources to create base-models for subsequent fine-tuning. In this talk, we develop a pre-training toolkit. Drawing from empirical findings, we present methodologies…
Robot Learning by Understanding Egocentric Videos
April 22, 2024 | Saurabh GuptaAbstract: True gains of machine learning in AI sub-fields such as computer vision and natural language processing have come about from the use of large-scale diverse datasets for learning. In this talk, I will discuss how we can leverage large-scale diverse data in the form of egocentric videos (first-person…
Project Sidewalk: Crowd+AI Techniques to Map and Assess Every Sidewalk in the World
April 18, 2024 | Jon FroehlichAbstract: Sidewalks are critical to human mobility, local commerce, and environmentally sustainable cities. In this interactive talk, we will showcase our 12+ years of research in developing scalable techniques to map, assess, and visualize sidewalks throughout the world. See https://projectsidewalk.org for more…
Does Generative AI Infringe Copyright?
April 10, 2024 | James GrimmelmanAbstract: Discussion of the copyright-law aspects of generative AI, based on ["Talkin’ ’Bout AI Generation: Copyright and the Generative-AI Supply Chain"](https://james.grimmelmann.net/files/articles/talkin-bout-ai-generation.pdf) . Here's a blog about the paper he co-authored: https://genlaw.org/explainers…
Towards a more contextualized view of the web
April 3, 2024 | Sihao ChenAbstract: Today, search tools and language models are better than ever at directing users to the relevant information according to their needs. However, it remains difficult for the users to put the information in the context of other sources. The lack of proper infrastructures and tools to provide…
Cultivating Insights: AI-Infused Workflow Designs for Nurturing the Scientific Idea Garden
March 27, 2024 | Hyeonsu KangAbstract: The advancement of science, engineering, and design depends on scientists' cognitive abilities to innovate beyond existing ideas. While human cognition excels at detecting patterns and forming original ideas, it is also hampered by cognitive biases and limitations, such as working memory and processing…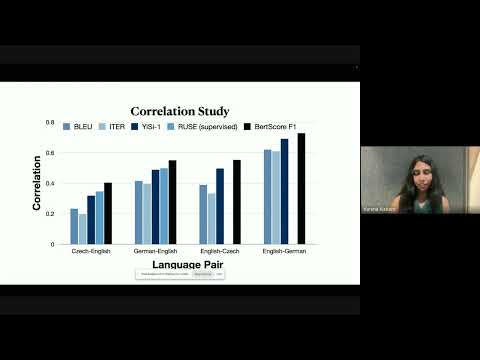
Optimization within Latent Spaces
March 25, 2024 | Varsha KishoreAbstract: Large language models are good at learning semantic latent spaces, and the resulting contextual embeddings from these models serve as powerful representations of information. In this talk, I present two novel uses of semantic distances in these latent spaces. In the first part, I introduce BERTScore, an…