Videos
See AI2's full collection of videos on our YouTube channel.Viewing 1-10 of 257 videos
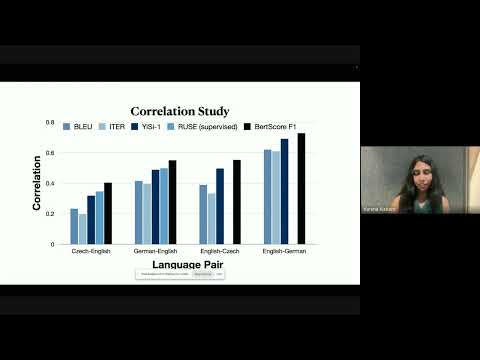
Optimization within Latent Spaces
May 25, 2024 | Varsha KishoreAbstract: Large language models are good at learning semantic latent spaces, and the resulting contextual embeddings from these models serve as powerful representations of information. In this talk, I present two novel uses of semantic distances in these latent spaces. In the first part, I introduce BERTScore, an…
Robot Learning by Understanding Egocentric Videos
April 22, 2024 | Saurabh GuptaAbstract: True gains of machine learning in AI sub-fields such as computer vision and natural language processing have come about from the use of large-scale diverse datasets for learning. In this talk, I will discuss how we can leverage large-scale diverse data in the form of egocentric videos (first-person…
Project Sidewalk: Crowd+AI Techniques to Map and Assess Every Sidewalk in the World
April 18, 2024 | Jon FroehlichAbstract: Sidewalks are critical to human mobility, local commerce, and environmentally sustainable cities. In this interactive talk, we will showcase our 12+ years of research in developing scalable techniques to map, assess, and visualize sidewalks throughout the world. See https://projectsidewalk.org for more…
Does Generative AI Infringe Copyright?
April 10, 2024 | James GrimmelmanAbstract: Discussion of the copyright-law aspects of generative AI, based on ["Talkin’ ’Bout AI Generation: Copyright and the Generative-AI Supply Chain"](https://james.grimmelmann.net/files/articles/talkin-bout-ai-generation.pdf) . Here's a blog about the paper he co-authored: https://genlaw.org/explainers…
Towards a more contextualized view of the web
April 3, 2024 | Sihao ChenAbstract: Today, search tools and language models are better than ever at directing users to the relevant information according to their needs. However, it remains difficult for the users to put the information in the context of other sources. The lack of proper infrastructures and tools to provide…
Cultivating Insights: AI-Infused Workflow Designs for Nurturing the Scientific Idea Garden
March 27, 2024 | Hyeonsu KangAbstract: The advancement of science, engineering, and design depends on scientists' cognitive abilities to innovate beyond existing ideas. While human cognition excels at detecting patterns and forming original ideas, it is also hampered by cognitive biases and limitations, such as working memory and processing…
Training Human-AI Teams
March 18, 2024 | Hussein MozannarAbstract: AI systems, including large language models (LLMs), are augmenting the capabilities of humans in settings such as healthcare and programming. I first showcase preliminary evidence of the productivity gains of LLMs in programming tasks. To understand opportunities for model improvements, I developed a…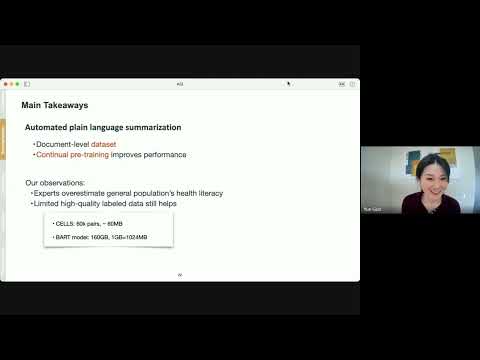
Making Health Knowledge Accessible Through Personalized Language Processing
March 11, 2024 | Yue GuoAbstract: The pandemic exposed the difficulties the general public faces when attempting to use scientific information to guide their health-related decisions. Though widely available in scientific papers, the information required to guide these decisions is often not accessible: medical jargon, scientific…
Figuring out how the world works: causality in a world full of real people
February 28, 2024 | Konrad KordingAbstract: Causality is key to many branches of science, engineering, and the alignment of AI systems. I will start by highlighting the difficulties of causal inference in the real world, and build some intuition about why in the real world causality is difficult while it seems easy in our mind. I will continue by…
Machine-Checked Proofs, and the Rise of Formal Methods in Mathematics
February 16, 2024 | Leonardo de MouraAbstract: The domains of mathematics and software engineering witness a rapid increase in complexity. As generative artificial intelligence emerges as a potential force in mathematical exploration, a pressing imperative arises: ensuring the correctness of machine-generated proofs and software constructs. The Lean…