Videos
See AI2's full collection of videos on our YouTube channel.Viewing 121-130 of 252 videos

Where’s the Data: A new approach to social science data search and discovery
February 5, 2019 | Julia LaneThe social sciences are at a crossroads The great challenges of our time are human in nature - terrorism, climate change, the use of natural resources, and the nature of work - and require robust social science to understand the sources and consequences. Yet the lack of reproducibility and replicability evident…
Understanding Time In Natural Language
January 25, 2019 | Qiang NingTime is an important dimension when we describe the world because the world is evolving over time and many facts are time-sensitive. Understanding time is thus an important aspect of natural language understanding and many applications may rely on it, e.g., information retrieval, summarization, causality, and…
Text Generation from Knowledge Graphs
January 11, 2019 | Rik Koncel-KedziorskiIn this talk I will introduce a new model for encoding knowledge graphs and generating texts from them. Graphical knowledge representations are ubiquitous in computing, but pose a challenge for text generation techniques due to their non-hierarchical structure and collapsing of long-distance dependencies…
Using cognitive science to evaluate and interpret neural language models
December 14, 2018 | Tal LinzenRecent technological advances have made it possible to train recurrent neural networks (RNNs) on a much larger scale than before. While these networks have proved effective in NLP applications, their limitations and the mechanisms by which they accomplish their goals are poorly understood. In this talk, I will…
Natural Language Interface for Web Interaction via Compositional Generation
December 12, 2018 | Panupong (Ice) PasupatNatural language understanding models have achieved good enough performance for commercial products such as virtual assistants. However, their scopes are mostly still limited to preselected domains or simpler sentences. I will present my line of work which extends natural language understanding in two frontiers…
Towards Agents that can See, Talk, and Act
December 11, 2018 | Abhisek DasBuilding intelligent agents that possess the ability to perceive the rich visual environment around us, communicate this understanding in natural language to humans and other agents, and execute actions in a physical environment, is a long-term goal of Artificial Intelligence. In this talk, I will present some of…
Learning Common Sense: A Grand Challenge for Academic AI Research
December 6, 2018 | Oren EtzioniDr. Oren Etzioni, Chief Executive Officer of the Allen Institute for AI and professor of computer science at the University of Washington, addresses one of the Holy Grails of AI: acquiring, representing and utilizing common-sense knowledge, during a distinguished lecture series held at the Office of Naval…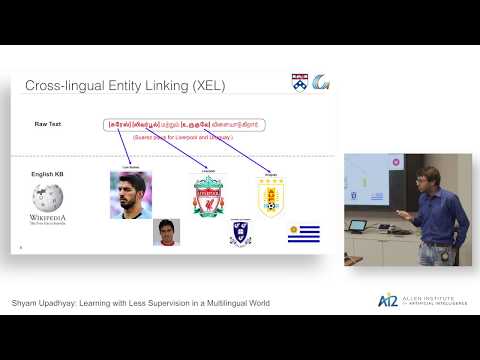
Learning with Less Supervision in a Multilingual World
November 16, 2018 | Shyam UpadhyayLack of annotated data is a constant obstacle in developing machine learning models, especially for natural language processing (NLP) tasks. In this talk, I explore this problem in the realm of Multilingual NLP, where the challenges become more acute as most of the annotation efforts in the NLP community have…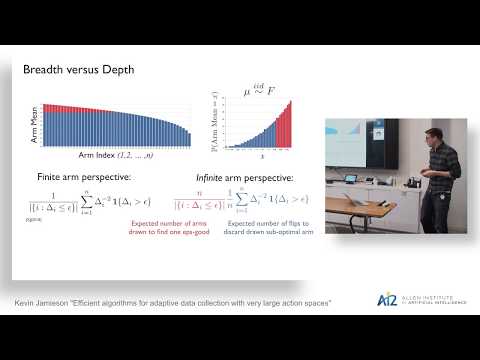
Efficient Algorithms for Adaptive Data Collection with Very Large Action Spaces
November 12, 2018 | Kevin JamiesonIn many science and industry applications, data-driven discovery is limited by the rate of data collection like the time it takes skilled labor to operate a pipette or the cost of expensive reagents or use of experimental apparatuses. When measurement budgets are necessarily small, adaptive data collection that…
Rational Recurrences: Bridging CNNs, RNNs, and Weighted Finite-State Machines
October 26, 2018 | Sam ThomsonIs there a class of models that perform competitively with LSTMs, yet are interpretable, parallelizable, data-efficient, and whose mathematical properties are already well-studied? I will present a recent line of work where we show that weighted finite-state automata (WFSAs) can be made unreasonably effective…